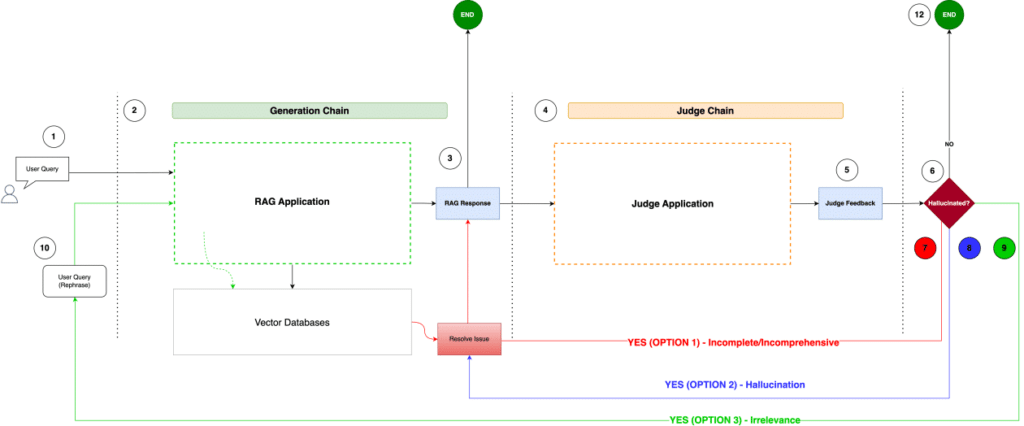
Las aplicaciones de inteligencia artificial generativa están revolucionando la productividad empresarial al ofrecer soluciones de respuesta a preguntas. Estas herramientas son impulsadas por arquitecturas sofisticadas, como la Generación Aumentada por Recuperación (RAG), flujos de trabajo agentivos, y modelos de lenguaje de gran escala (LLMs). Sin embargo, para que estos asistentes sean efectivos y confiables, es fundamental contar con una base sólida de datos verídicos y un marco de evaluación riguroso.
Los datos de referencia en inteligencia artificial, conocidos como datos fácticos, son cruciales para medir la calidad de un sistema. Al establecer un resultado esperado, se pueden realizar evaluaciones determinísticas que permiten la creación de referencias personalizadas. Estas son esenciales para monitorear y mejorar el rendimiento de los asistentes de IA y para realizar comparaciones estadísticas entre diferentes soluciones.
A través de procesos como las métricas de Conocimiento Factual y Precisión de QA de FMEval, se interrelaciona la generación de datos verídicos con las métricas de evaluación. Para asegurar la calidad máxima, la métrica de evaluación debe guiar la elaboración de estos datos verídicos.
El artículo destaca las mejores prácticas para aplicar LLMs en la creación de datos verídicos, utilizando FMEval a nivel empresarial. FMEval, parte de Amazon SageMaker Clarify, ofrece una suite de métricas estandarizadas para asegurar la calidad y responsabilidad de los asistentes de IA.
Los equipos pueden iniciar la generación de datos verídicos mediante la curación humana de un pequeño conjunto de datos de preguntas y respuestas. Este proceso, apoyado por expertos en la materia, busca afinar temprano el alineamiento de datos y promover conversaciones críticas sobre qué evaluar para el negocio.
Para ampliar la escala de estos datos, se recomienda un enfoque basado en riesgos y una estrategia de creación de prompts con LLMs. Aunque los LLMs facilitan la generación de datos referencia, no deben reemplazar la pericia de los expertos en la materia. La evaluación debe integrar ambos elementos para alinear los datos con el valor empresarial.
El enfoque propuesto asegura que las evaluaciones, realizadas con FMEval, sean consistentes con las expectativas del negocio, permitiendo una medición efectiva de la calidad y responsabilidad de los asistentes.
Este método ofrece un marco claro para que las organizaciones desarrollen y evalúen asistentes de inteligencia artificial generativa, proporcionándoles las herramientas necesarias para competir en un mercado que cambia rápidamente.



