La adopción de inteligencia artificial en el ámbito empresarial continúa su avance con soluciones cada vez más sofisticadas, destinadas a satisfacer las crecientes demandas de personalización y eficiencia. Una de las innovaciones más destacadas en este terreno es el uso de modelos de lenguaje generadores a gran escala, facilitado por plataformas como Amazon Bedrock. Esta herramienta se ha posicionado como un servicio integral que gestiona tanto modelos de startups emergentes como los propios de Amazon, ofreciendo una API para que las empresas puedan elegir el modelo que mejor se adapte a sus necesidades.
Amazon Bedrock no solo da acceso a estos avanzados modelos de lenguaje, sino que también permite su personalización para ajustarse a requerimientos específicos. Este proceso de personalización, a menudo crucial para aplicaciones complejas o especializadas, se logra mediante técnicas de ajuste fino. Este enfoque consiste en entrenar modelos preentrenados con datos específicos, potenciando su rendimiento en casos de uso determinantes. No obstante, la recolección y mantenimiento de datos de alta calidad sigue siendo un desafío considerable.
Frente a esta situación, la creación de datos sintéticos ha surgido como una estrategia prometedora. Al generar datos de entrenamiento sintéticos mediante un modelo de lenguaje de mayor capacidad, se optimiza el tiempo de respuesta y se disminuye la necesidad de grandes recursos, lo cual es especialmente ventajoso en contextos donde los datos originales escasean.
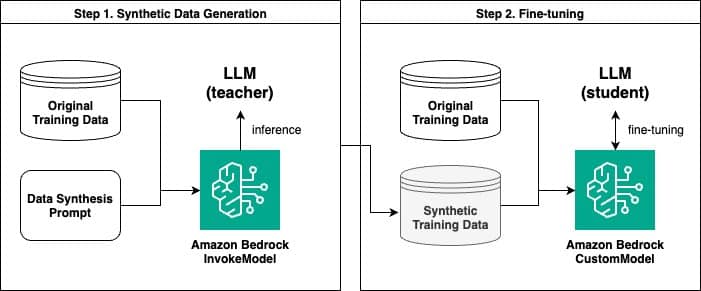
Dentro de este marco, Amazon Bedrock facilita la generación de datos sintéticos, permitiendo posteriormente el ajuste fino del modelo con la nueva información. Un reciente estudio evidenció el procedimiento, que involucra dos pasos clave: la generación inicial de datos sintéticos a través de la API InvokeModel y, posteriormente, la adecuación del modelo con un enfoque personalizado.
La técnica especifica se basa en la generación de pares de preguntas y respuestas sintéticas, donde un modelo maestro de mayor tamaño entrega conocimientos y contextos útiles para entrenar un modelo estudiante más pequeño. Este proceso, comparable a la destilación de conocimiento en el ámbito del aprendizaje profundo, ha probado ser eficaz para mejorar el rendimiento de los modelos entrenados.
Comparaciones entre modelos entrenados con datos originales y sintéticos mostraron que, aunque los modelos afinados con datos sintéticos frecuentemente superaron en rendimiento a sus contrapartes originales, aún no alcanzan a superar a aquellos modelos entrenados con grandes cantidades de datos reales.
Además, la implementación de evaluaciones con base en modelos de lenguaje como jueces, que evalúan la calidad de las respuestas generadas, ha revelado que los modelos afinados con ejemplos sintéticos muestran un notable desempeño comparativo.
En conclusión, la capacidad de Amazon Bedrock para generar datos sintéticos y personalizar modelos de lenguaje abre una vía efectiva para abordar la escasez de datos en muchas aplicaciones empresariales. Conforme las empresas buscan maneras más eficientes y costo-efectivas de personalización de modelos de lenguaje, estas innovaciones podrían ser vitales para su éxito futuro.



