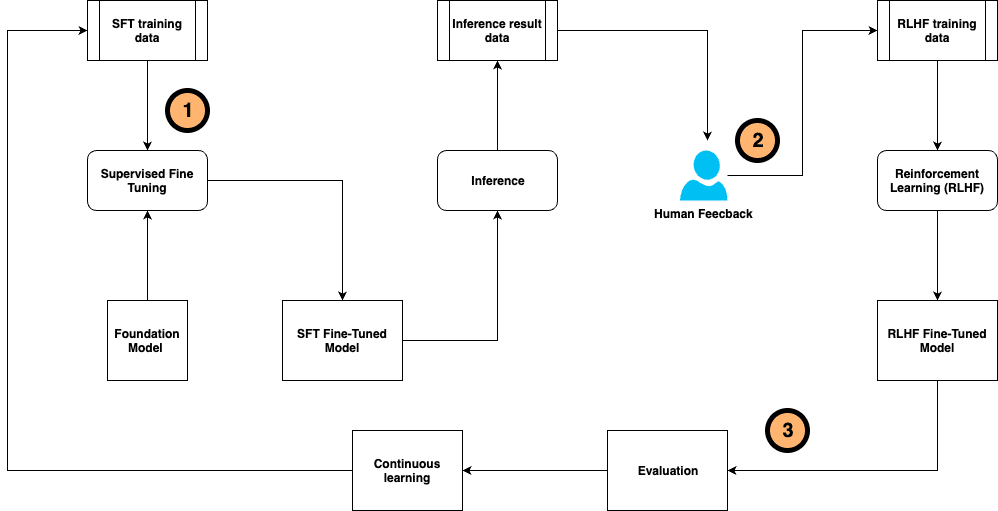
El avance en el ajuste fino de modelos de lenguaje grandes (LLM) preentrenados ha tomado un rol crucial en el ámbito tecnológico, permitiendo a los usuarios personalizar estos modelos para mejorar su desempeño en tareas específicas. Este proceso continuo garantiza que los modelos refinados mantengan su precisión y efectividad en escenarios en constante cambio, adaptándose a la evolución de los datos y evitando la degradación del rendimiento con el tiempo. La integración del ajuste fino continuo facilita la incorporación de retroalimentación humana, la corrección de errores y la adaptación a aplicaciones del mundo real.
Una técnica clave en este proceso es el ajuste fino supervisado (SFT) junto con la afinación de instrucciones, que se apoya en conjuntos de datos y directrices proporcionados por humanos. A medida que llegan comentarios sobre las respuestas generadas por el modelo, se implementa el aprendizaje por refuerzo basado en retroalimentación humana (RLHF) para orientar las respuestas del LLM, recompensando aquellas salidas que se alinean con las preferencias humanas.
No obstante, la obtención de resultados precisos y responsables de modelos LLM finamente ajustados requiere un esfuerzo considerable por parte de expertos. La anotación manual de un gran volumen de datos para el ajuste fino y la recolección de comentarios del usuario representan tareas que consumen muchos recursos y tiempo. Además, el proceso continuo de ajuste fino implica coordinar múltiples pasos: generación de datos, entrenamiento del LLM, recolección de retroalimentación y alineación de preferencias.
Para mitigar estos retos, se ha diseñado un marco innovador de ajuste fino auto-instruido continuo. Este sistema simplifica y unifica la generación y anotación de datos de entrenamiento, el entrenamiento y evaluación del modelo, además de la recolección de retroalimentación humana y la alineación con las preferencias de los usuarios. Se presenta así un sistema de IA compuesto que promete mejorar la eficiencia del flujo de trabajo, optimizando rendimiento, versatilidad y reutilización.
El marco auto-instruido continuo permite personalizar el modelo base mediante muestras de entrenamiento etiquetadas por humanos y la retroalimentación humana post-inferencia del modelo. Este flujo de trabajo se ejecuta continuamente para adaptarse a entornos dinámicos.
En relación a este enfoque, el sistema de IA compuesto ha sido diseñado para sortear las complicaciones que presentan los modelos monolíticos. La interacción entre múltiples componentes, como llamadas a diversos modelos, recuperadores y herramientas externas, permite la creación de soluciones más sofisticadas y eficientes.
Para facilitar la construcción y optimización de estos sistemas compuestos, se introdujo DSPy, un marco de programación de Python de código abierto. Este framework apoya a los desarrolladores en la creación de aplicaciones LLM utilizando programación modular y declarativa. Está diseñado para optimizar tanto los resultados como la experiencia del usuario en aplicaciones de IA, permitiendo mayor flexibilidad en el desarrollo y mantenimiento de soluciones.
En resumen, el desarrollo de un sistema de ajuste fino continuo y auto-instruido no solo mejora la precisión y el rendimiento de los modelos de lenguaje, sino que también establece un marco que maximiza la reutilización y la adaptabilidad ante la incesante evolución de los datos y las demandas del usuario.



