En la actualidad, el uso de aplicaciones de inteligencia artificial generativa en el campo de la salud está experimentando un avance significativo gracias a la implementación de nuevas metodologías de evaluación. Recientemente, un análisis exhaustivo sobre técnicas avanzadas como el ajuste fino de modelos de lenguaje grande y la ingeniería de prompts fue llevado a cabo, mostrando sus capacidades para generar impresiones precisas a partir de informes de radiología.
Una técnica destacada es la Generación Aumentada por Recuperación (RAG), la cual combina modelos de lenguaje con bases de conocimiento externas. Esta metodología ha demostrado ser particularmente efectiva para reducir errores y mejorar la precisión en aplicaciones médicas. La RAG opera recuperando en tiempo real la información médica relevante, lo cual proporciona respuestas más fiables y contextualmente apropiadas, un requerimiento crítico en el sector salud donde la precisión es imperativa.
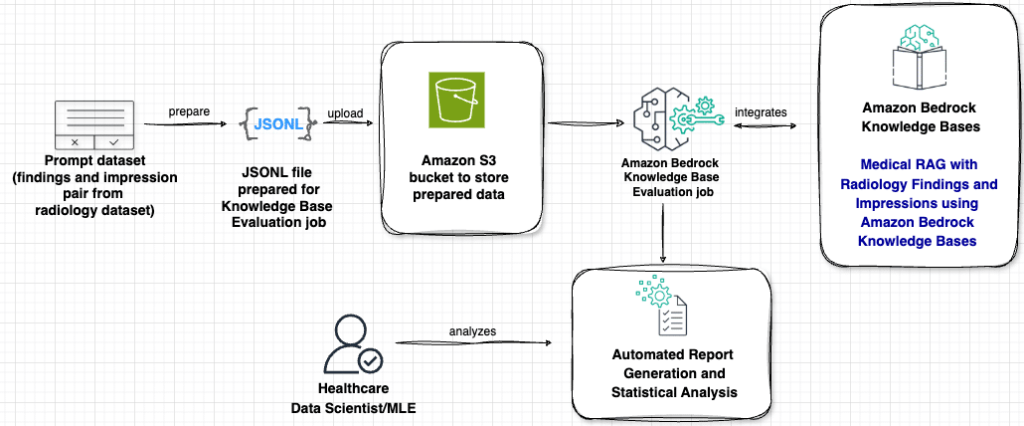
Hasta ahora, el rendimiento de estos sistemas se evaluaba con técnicas tradicionales como las métricas ROUGE, comúnmente usadas para tareas de resumen generales. Sin embargo, estas no son capaces de medir eficazmente la integración del conocimiento médico recuperado, ni de asegurar precisión clínica. Ante este desafío, se ha desarrollado un nuevo enfoque de evaluación que utiliza el modelo de lenguaje grande (LLM) como juez, en combinación con Amazon Bedrock. Este marco revolucionario aborda los desafíos específicos de los sistemas RAG en el ámbito de la salud, garantizando que tanto el conocimiento médico recuperado como el contenido generado cumplan con exigentes estándares de claridad y precisión clínica.
El uso de LLM como juez introduce una forma de evaluación más completa y matizada, que tiene en cuenta no solo la recuperación de información sino también la calidad y precisión clínica del contenido generado. Esto es esencial en un entorno donde las aplicaciones médicas de RAG son cada vez más comunes, integrándose en escenarios clínicos que exigen altos estándares de exactitud.
Este marco de evaluación es implementado con Amazon Bedrock y permite comparar el rendimiento de diferentes modelos generadores, como Claude de Anthropic y Nova de Amazon. Además, introduce una nueva función de evaluación RAG que optimiza parámetros de la base de conocimiento y analiza la calidad de recuperación. Estas innovaciones no solo establecen nuevos puntos de referencia para la evaluación de aplicaciones médicas de RAG, sino que también proporcionan herramientas prácticas para que los profesionales construyan aplicaciones de inteligencia artificial confiables en entornos clínicos. Estas mejoras son un paso crucial para asegurar que las aplicaciones basadas en inteligencia artificial en el sector salud puedan cumplir con los estrictos requisitos que demandan los contextos médicos actuales.



