
En el mundo del hardware hay dogmas que se repiten generación tras generación. Uno de los más conocidos es la curva de la bañera: ese gráfico con forma de “U” que durante décadas ha servido para explicar la fiabilidad de casi cualquier equipo. Al principio habría un bache de fallos tempranos; después, una meseta de calma; y, al final de la vida útil, un repunte de averías por desgaste. Orden en el caos, ingeniería de libro.
La realidad, medida a lo largo de 13 años de datos continuos en centros de datos, está contando otra historia. Esa es la conclusión de Backblaze, la compañía que publica trimestralmente su base de datos de fallos de discos duros y que se ha convertido en una referencia para cualquiera que diseña o mantiene almacenamiento. Su último gran repaso a la fiabilidad por edades dice, en esencia, dos cosas: los HDD rinden mejor y duran más en entornos de CPD, y la famosa curva de la bañera no describe bien lo que está ocurriendo hoy.
Tres fotografías que rompen un mito
Backblaze ha comparado la forma de la curva en 2013, 2021 y 2025. Los números llamativos son estos:
- 2013: pico de tasa anualizada de fallos (AFR) del 13,73 % en torno a los 3 años y 3 meses (otro máximo cercano del 13,30 % a 3 años y 9 meses).
- 2021: pico de 14,24 %, pero mucho más tarde, a los 7 años y 9 meses.
- 2025: pico de 4,25 % a los 10 años y 3 meses.
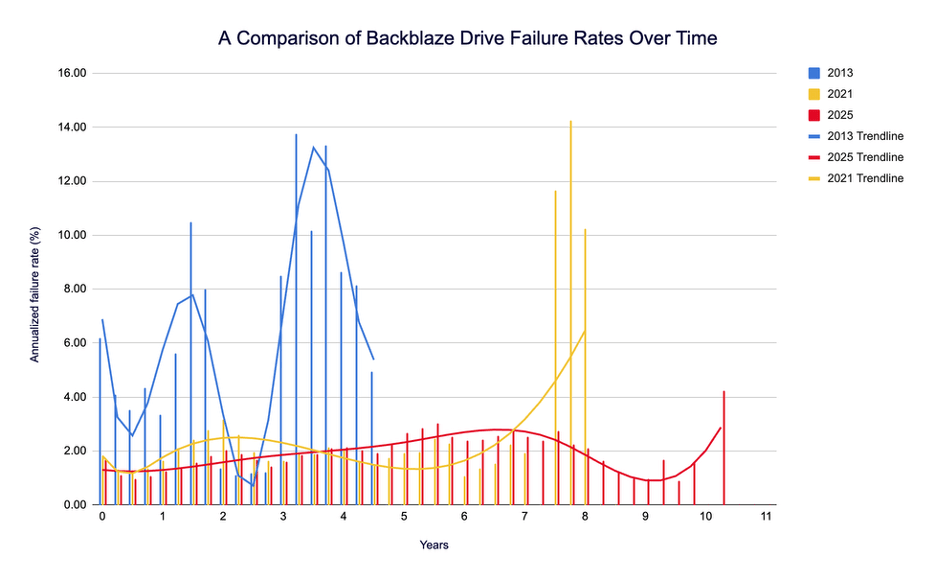
Traducido: el máximo de averías se retrasa (hasta superar los diez años) y, cuando llega, la altura del pico es aproximadamente un tercio de lo que Backblaze vio en 2013 y 2021. En el frente opuesto, los fallos tempranos también se han moderado claramente: entre 0 y 1 año de vida, la AFR apenas rebasa el 1,30 %. A modo de referencia, la AFR trimestral más reciente de la flota está en 1,36 %.
Para el lector de componentes informáticos, esos porcentajes importan. Implican menos sorpresas en el arranque de la vida del disco, mesetas más estables durante años y un final menos abrupto… que además puede no verse si el operador retira la unidad por estrategia antes de que falle.
Contexto que un integrador no debería pasar por alto
Comparar curvas separadas por una década sin contexto puede conducir a conclusiones simplistas. Backblaze pone sobre la mesa varios cambios relevantes:
- Tamaño y composición de la flota. En 2013 estaban en el orden de 35.000 discos (y más de 100 PB en 2014); en 2021 ya eran ~206.928; y en 2025 rondan los 317.230. A mayor muestra, menos dientes de sierra estadísticos y más confianza en la tendencia agregada.
- Tipos de unidad y “drive farming”. En los inicios, la flota incluía muchos discos “de consumo” reconvertidos a rack (llegaron a “descapotar” unidades sacándolas de sus cajas externas comerciales). La operación era cuidadosa, pero es un factor de riesgo adicional frente a la compra de grandes lotes orientados al CPD que hacen hoy.
- Cohortes de compra. Comprar a granel significa que muchos discos idénticos (mismo modelo y lote) entran a la vez. Si un modelo sale “bueno”, aplacas la curva; si sale “rana”, concentras fallos. Este efecto no lo captura el modelo teórico de la bañera.
- Decom distinto. La estrategia actual desmantela algunas unidades que siguen funcionando (por riesgo o por escalado de capacidad). Resultado: bajas la población en tramos finales sin generar los picos de fallos que verías si estiras cada disco “hasta el último byte”.
- Entorno y operación. 13 años dan para cambiar CPDs (Sacramento, Phoenix, Ámsterdam…), estándares térmicos, vibración, firmware y higiene de flota. Todo eso empuja a una curva real más plana y más tardía.
Para un ensamblador o un responsable de compras en el canal, la moraleja es directa: no extrapoles datos de hace diez años a decisiones de hoy y no mezcles manzanas con peras (modelo, lote y entorno importan).
¿Se ha roto la curva de la bañera?
Más que “rota”, está superada como explicación única. La curva simplifica al tratar el tiempo como la variable dominante y suponer que todos los dispositivos trabajan igual en un entorno idéntico. La realidad del CPD introduce dimensiones extra: modelo y lote, firmware, temperatura, vibración, cargas reales, estándares de aceptación y retirada. En ese mundo con más variables, la forma típica que emerge en 2025 es: afectación mínima al principio, meseta larga de AFR baja, y repunte tardío mucho más suave.
Esto no significa que tu HDD doméstico vaya a durar “X años garantizados”. Significa que, en uso de CPD bien gestionado, las probabilidades de fallo temprano son bajas y el “fin de vida” se desplaza a la derecha.
Lo que significa para quien compra y vende discos
1) Modelo a modelo, no “marca a marca”
La información de Backblaze es agregada; lo que tú necesitas para decidir es modelo por modelo. Incluso en una tendencia positiva, hay variabilidad entre SKUs. Revisa AFR por modelo y por edad, RMA y notas de firmware. Una mala serie puede arruinarte un trimestre.
2) Compra en oleadas, no de una tacada
Las cohortes importan. Si compras 2.000 unidades de un SKU nuevo y resulta problemático, concentras el dolor. Comprar en oleadas te permite medir y corregir. Y mezcla proveedores/series de forma controlada para no tener todos los huevos en la misma cesta.
3) Diseña la retirada (decom) pensando en riesgo, no en romanticismo
“Exprimir hasta que caiga” suena eficiente, pero eleva el riesgo de picos al final y golpes a la operativa. Define criterios de decom (horas, health, latencia, errores de E/S, vibración del chasis) en función de tu RTO/RPO y tu flujo de backups. Y presupuéstalo: la continuidad se paga.
4) SMART no es oráculo
Es útil, pero no predice todo. Añade telemetría de latencia (p95/p99), errores de E/S, reintentos, temperatura sostenida y vibración por rack o bandeja. A veces “el síntoma” aparece en la cola de disco y en el tiempo de servicio antes que en un atributo SMART.
5) El entorno suma (o resta) fiabilidad
Discos en bandejas mal acopladas, vibración por ventiladores, hotspots térmicos o picos de alimentación suben la AFR real. En un PC de sobremesa esto es difícil de vigilar. En un rack, es cuestión de diseño y sensórica.
Nota: el debate CMR vs. SMR no aparece en los datos que Backblaze ha puesto sobre la mesa en este repaso. Si tu carga tiene muchas escrituras aleatorias, sabes que SMR no es tu amigo. Si es mayoritariamente secuencial y de lectura, puede convivir. Pero esa decisión va por workload, no por curva agregada.
Para el canal y el integrador: cómo leer (bien) los gráficos de 2025
- AFR inicial por debajo de 1,3 % (0–1 año): buena noticia para DOA y RMA tempranos.
- Pico tardío (10 años) y moderado (4,25 %): si tu ventana de depreciación/renovación es 3–5–7 años, ni lo ves.
- Meseta estable durante la mayor parte de la vida: menos variabilidad, mejor TCO por bahía.
- Flotas grandes ≠ “discos indestructibles”: lo que ves es tendencia; el riesgo puntual por modelo sigue ahí.
¿Y para el usuario entusiasta?
Si montas un NAS doméstico o un PC con varios discos, la lección práctica es doble: elige bien el modelo (no todos los 8 TB son iguales) y mima el entorno (temperatura, vibración, alimentación decente). Aunque los números de Backblaze son de CPD, la tendencia apunta a más vida útil media y menos fallos tempranos. Aun así, backup 3-2-1 y SMART + pruebas regulares: no hay curva que sustituya a una copia verificada.
Una última idea para fabricantes
La historia no devalúa el trabajo de los fabricantes de HDD; al contrario. Si el pico de AFR se desplaza de 3–4 años a ~10 y baja del ~14 % al 4 %, hay ingeniería y proceso detrás: densidades, firmware, control de vibración, actuadores, sellado, recubrimientos… y mejores estándares del lado del CPD. El mercado del componente vive de confianza. Publicar datos útiles (test de estrés por modelo, perfiles de carga, firmware validado) sigue siendo el mejor argumento de ventas.

Preguntas frecuentes
¿Sigue sirviendo la “curva de la bañera” para hablar de fiabilidad de HDD?
Como intuición, sí: hay fallos tempranos, una meseta y un final. Pero los datos de CPD reales la hacen incompleta. Hoy la foto es AFR muy baja al inicio, meseta larga y repunte final tardío y suave (pico 2025: 4,25 % a 10 años y 3 meses).
¿Por qué el pico de fallos baja y se retrasa tanto en 2025?
Por varios factores combinados: muestras mucho mayores, mejor operación (compra por lotes, decom con criterio, entornos más estables), y un parque de modelos más robusto para CPD. También influye retirar discos antes de que fallen.
¿Qué significa un AFR ~1,3 % el primer año para el canal?
Menos DOA y menos RMA tempranas. A nivel de plataforma, más tiempo de servicio antes de tocar bahías y menos ruido en los primeros 12 meses.
¿Puedo extrapolar estos datos a SSD?
No. El análisis al que hacemos referencia es de HDD en centro de datos. La fiabilidad de SSD obedece a otras variables (TBW, DWPD, controladora, firmware, temperatura). Mezclar curvas es mala práctica.
¿Cuál es la decisión más importante al comprar discos para un servidor o NAS?
Elegir el modelo correcto para tu carga (secuencial/aleatoria, lectura/escritura), comprar en oleadas para evitar cohesión de riesgos, vigilar métricas (SMART, latencias, errores de E/S) y definir política de retirada acorde a tu RTO/RPO. La tendencia es buena, pero el diseño de tu plataforma sigue marcando la diferencia.
En resumen: los HDD han mejorado. El “gran repunte” ya no llega a mitad de vida, sino muy tarde, y con una intensidad mucho menor. Buenas noticias para quien integra y para quien mantiene; pero, como siempre en sistemas, la arquitectura y las prácticas operativas siguen siendo el 50 % del resultado.
vía: Revista Cloud



