Los modelos de lenguaje de gran tamaño (LLMs, por sus siglas en inglés) han revolucionado el ámbito del procesamiento del lenguaje natural, permitiendo la comprensión y generación de textos que imitan el estilo humano. Estos sistemas, entrenados con enormes cantidades de datos abarcan múltiples temas y dominios, y se están optimizando continuamente para mejorar su desempeño en aplicaciones específicas mediante técnicas de ajuste fino y aprendizaje a partir de pocos ejemplos. No obstante, el tremendo poder computacional que requieren representa un desafío importante para cumplir con las necesidades de respuesta inmediata que demandan aplicaciones como la traducción en tiempo real o los asistentes de voz conversacionales.
En este contexto, un reciente desarrollo tecnológico promete abordar este reto: el marco denominado Medusa. Esta innovación incrementa la velocidad de inferencia de los LLMs al añadir cabezas adicionales que permiten predecir múltiples tokens al mismo tiempo. Con la implementación de Medusa-1, se ha logrado doblar la celeridad de inferencia, manteniendo la calidad del modelo. En experimentos recientes, al trabajar con un conjunto de datos de prueba, se alcanzó un incremento de 1.8 veces en velocidad.
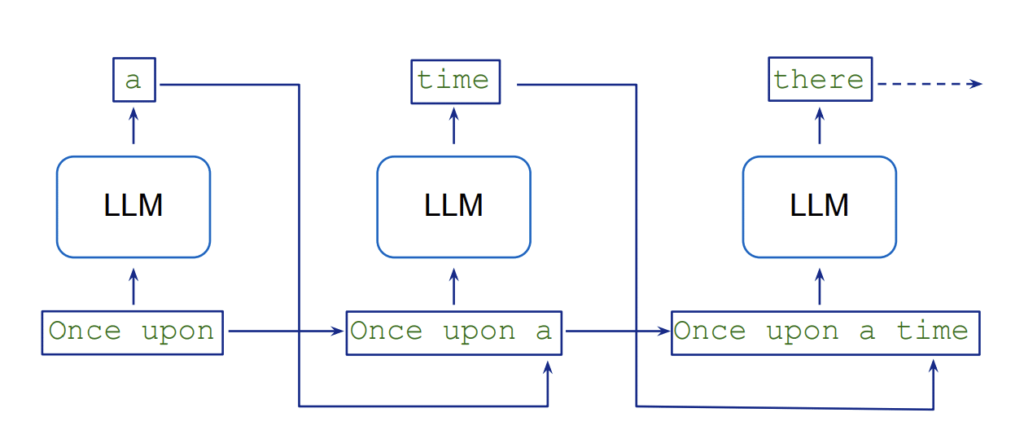
El proceso de generación de texto en los LLMs es intrínsecamente secuencial, lo que provoca una latencia mientras cada nuevo token depende de los mensajes anteriores. Esto conlleva un requerimiento de varias pasadas del modelo y un elevado consumo de recursos. Para paliar esta situación, la técnica de «decodificación especulativa» utiliza un modelo liviano para crear continuaciones potenciales en paralelo que son luego validadas por un modelo más preciso. Medusa simplifica este procedimiento introduciendo cabezas de decodificación que generan candidatos simultáneamente, reduciendo así los pasos secuenciales necesarios.
Medusa ha demostrado notables mejoras en velocidad, alcanzando hasta 2.8 veces el rendimiento de inferencia dependiendo del tamaño y la complejidad del modelo. Este sistema es compatible con modelos como Llama y Mistral, aunque su uso puede requerir adicional memoria dependiendo de la cantidad de cabezas incluidas. Capacitar estas cabezas adicionales implica un compromiso en tiempo y recursos, lo que es importante considerar al planificar proyectos. Por otra parte, el marco está diseñado para trabajar con un tamaño de lote de uno, haciéndolo ideal para aplicaciones que necesitan bajas latencias.
Desde la preparación de conjuntos de datos hasta la implementación en un endpoint de Amazon SageMaker AI, el marco Medusa facilita la aceleración de la inferencia en LLMs, optimizando los tiempos de respuesta y enriqueciendo la experiencia del usuario. En un momento en que las empresas buscan explotar al máximo el potencial de los LLMs, soluciones como Medusa serán esenciales para enfrentar los desafíos operativos y de calidad que plantea la generación automatizada de texto.



